 |  |

| |
It is not enough to have your server and service up and running. The server must be maintained and monitored even when everything seems to be fine. This includes security auditing as well as keeping an eye on the amount of remaining unused disk space, available RAM, the system's load, etc.
If these chores are forgotten, sooner or later the system will crash, either because it has run out of free disk space, all available RAM has been used and the system has started to swap heavily, or it has been broken into. The last issue is much too broad for this book's scope, but the others are quite easily addressed if you follow our advice.
Particular systems might require maintenance chores that are not covered here, but this section highlights some of the most important general tasks.
Apache generally logs all the web server access events in the access_log file, whereas errors and warnings go into the error_log file. The access_log file can later be analyzed to report server usage statistics, such as the number of requests made in different time spans, who issued these requests, and much more. The error_log file is used to monitor the server for errors and warnings and to prompt actions based on those reports. Some systems do additional logging, such as storing the referrers of incoming requests to find out how users have learned about the site.
The simplest logging technique is to dump the logs into a file opened for appending. With Apache, this is as simple as specifying the logging format and the file to which to log. For example, to log all accesses, use the default directive supplied in httpd.conf:
LogFormat "%h %l %u %t \"%r\" %>s %b" common CustomLog /home/httpd/httpd_perl/logs/access_log common
This setting will log all server accesses to a file named /home/httpd/httpd_perl/logs/access_log using the format specified by the LogFormat directive—in this case, common. Please refer to the Apache documentation for a complete explanation of the various tokens that you can use when specifying log formats. If you're tempted to change the format of the log file, bear in mind that some log analysis tools may expect that only the default or one of a small subset of logging formats is used.
The only risk with log files is their size. It is important to keep log files trimmed. If they are needed for later analysis, they should be rotated and the rotation files should be moved somewhere else so they do not consume disk space. You can usually compress them for storage offline.
The most important thing is to monitor log files for possible sudden explosive growth rates. For example, if a developer makes a mistake in his code running on the mod_perl server and the child processes executing the code start to log thousands of error messages a second, all disk space can quickly be consumed, and the server will cease to function.
The first issue is solved by having a process that rotates the logs run by cron at certain times (usually off-peak hours, if this term is still valid in the 24-hour global Internet era). Usually, log rotation includes renaming the current log file, restarting the server (which creates a fresh new log file), and compressing and/or moving the rotated log file to a different disk.
For example, if we want to rotate the access_log file, we could do:
panic% mv access_log access_log.renamed panic% apachectl graceful panic% sleep 5 panic% mv access_log.renamed /some/directory/on/another/disk
The sleep delay is added to make sure that all children complete requests and logging. It's possible that a longer delay is needed. Once the restart is completed, it is safe to use access_log.renamed.
There are several popular utilities, such as rotatelogs and cronolog, that can perform the rotation, although it is also easy to create a basic rotation script. Example 5-10 shows a script that we run from cron to rotate our log files.
#!/usr/local/bin/perl -Tw
# This script does log rotation. Called from crontab.
use strict;
$ENV{PATH}='/bin:/usr/bin';
delete @ENV{qw(IFS CDPATH ENV BASH_ENV)};
### configuration
my @logfiles = qw(access_log error_log);
umask 0;
my $server = "httpd_perl";
my $logs_dir = "/home/httpd/$server/logs";
my $restart_command = "/home/httpd/$server/bin/apachectl restart";
my $gzip_exec = "/usr/bin/gzip -9"; # -9 is maximum compression
my ($sec, $min, $hour, $mday, $mon, $year) = localtime(time);
my $time = sprintf "%0.4d.%0.2d.%0.2d-%0.2d.%0.2d.%0.2d",
$year+1900, ++$mon, $mday, $hour, $min, $sec;
chdir $logs_dir;
# rename log files
foreach my $file (@logfiles) {
rename $file, "$file.$time";
}
# now restart the server so the logs will be restarted
system $restart_command;
# allow all children to complete requests and logging
sleep 5;
# compress log files
foreach my $file (@logfiles) {
system "$gzip_exec $file.$time";
}As can be seen from the code, the rotated files will include the date and time in their filenames.
As we mentioned earlier, there are times when the web server goes wild and starts to rapidly log lots of messages to the error_log file. If no one monitors this, it is possible that in a few minutes all free disk space will be consumed and no process will be able to work normally. When this happens, the faulty server process may cause so much I/O that its sibling processes cannot serve requests.
Although this rarely happens, you should try to reduce the risk of it occurring on your server. Run a monitoring program that checks the log file size and, if it detects that the file has grown too large, attempts to restart the server and trim the log file.
Back when we were using quite an old version of mod_perl, we sometimes had bursts of "Callback called exit" errors showing up in our error_log. The file could grow to 300 MB in a few minutes.
Example 5-11 shows a script that should be executed from crontab to handle situations like this. This is an emergency solution, not to be used for routine log rotation. The cron job should run every few minutes or even every minute, because if the site experiences this problem, the log files will grow very rapidly. The example script will rotate when error_log grows over 100K. Note that this script is still useful when the normal scheduled log-rotation facility is working.
#!/bin/sh
S=`perl -e 'print -s "/home/httpd/httpd_perl/logs/error_log"'`;
if [ "$S" -gt 100000 ] ; then
mv /home/httpd/httpd_perl/logs/error_log \
/home/httpd/httpd_perl/logs/error_log.old
/etc/rc.d/init.d/httpd restart
date | /bin/mail -s "error_log $S kB" admin@example.com
fiOf course, a more advanced script could be written using timestamps and other bells and whistles. This example is just a start, to illustrate a basic solution to the problem in question.
Another solution is to use ready-made tools that are written for this purpose. The daemontools package includes a utility called multilog that saves the STDINstream to one or more log files. It optionally timestamps each line and, for each log, includes or excludes lines matching specified patterns. It automatically rotates logs to limit the amount of disk space used. If the disk fills up, it pauses and tries again, without losing any data.
The obvious caveat is that it does not restart the server, so while it tries to solve the log file-handling issue, it does not deal with the problem's real cause. However, because of the heavy I/O induced by the log writing, other server processes will work very slowly if at all. A normal watchdog is still needed to detect this situation and restart the Apache server.
If you are running more than one server on the same machine, Apache offers the choice of either having a separate set of log files for each server, or using a central set of log files for all servers. If you are running servers on more than one machine, having them share a single log file is harder to achieve, but it is possible, provided that a filesharing system is used (logging into a database, or a special purpose application like syslog).
There are a few file-sharing systems that are widely used:
Apache permits the location of the file used for logging purposes to be specified, but it also allows you to specify a program to which all logs should be piped. To log to a program, modify the log handler directive (for example, CustomLog) to use the logging program instead of specifying an explicit filename:
LogFormat "%h %l %u %t \"%r\" %>s %b" common CustomLog "| /home/httpd/httpd_perl/bin/sqllogger.pl" common
Logging into a database is a common solution, because you can do insertions from different machines into a single database. Unless the logger is programmed to send logs to a few databases at once, this solution is not reliable, since a single database constitutes a single failure point. If the database goes down, the logs will be lost. Sending information to one target is called unicast (see Figure 5-6), and sending to more than one target is called multicast (see Figure 5-7). In the latter case, if one database goes down, the others will still collect the data.
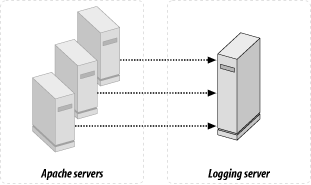
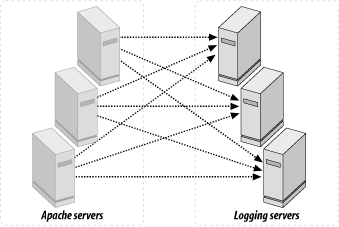
Another solution is to use a centralized logger program based on syslog(3) to send all logs to a central location on a master host. syslog(3) is not a very scalable solution, because it's slow. It's also unreliable—it uses UDP to send the data, which doesn't ensure that the data will reach its destination. This solution is also unicast: if the master host goes down, the logs will be lost.
One advanced system that provides consolidated logging is mod_log_spread. Based on the group communications toolkit Spread, using IP multicast, mod_log_spread provides reliable, scalable centralized logging whith minimal performance impact on the web servers. For more information, see http://www.backhand.org/mod_log_spread/.
Before we delve into swapping process details, let's look briefly at memory components and memory management.
Computer memory is called RAM (Random Access Memory). Reading and writing to RAM is faster than doing the same operations on a hard disk, by around five orders of magnitude (and growing). RAM uses electronic memory cells (transistors) with no moving parts, while hard disks use a rotating magnetic medium. It takes about one tenth of a microsecond to write to RAM but something like ten thousand microseconds to write to hard disk. It is possible to write just one byte (well, maybe one word) to RAM, whereas the minimum that can be written to a disk is often four thousand or eight thousand bytes (a single block). We often refer to RAM as physical memory.
A program may take up many thousands of bytes on disk. However, when it is executed normally, only the parts of the code actually needed at the time are loaded into memory. We call these parts segments.
On most operating systems, swap memory is used as an extension for RAM and not as a duplication of it. Assuming the operating system you use is one of those, if there is 128 MB of RAM and a 256 MB swap partition, there is a total of 384 MB of memory available. However, the extra (swap) memory should never be taken into consideration when deciding on the maximum number of processes to be run (we will show you why in a moment). The swap partition is also known as swap space or virtual memory.
The swapping memory can be built from a number of hard disk partitions and swap files formatted to be used as swap memory. When more swap memory is required, as long as there is some free disk space, it can always be extended on demand. (For more information, see the mkswap and swapon manpages.)
System memory is quantified in units called memory pages. Usually the size of a memory page is between 1 KB and 8 KB. So if there is 256 MB of RAM installed on the machine, and the page size is 4 KB, the system has 64,000 main memory pages to work with, and these pages are fast. If there is a 256-MB swap partition, the system can use yet another 64,000 memory pages, but they will be much slower.
When the system is started, all memory pages are available for use by the programs (processes). Unless a program is really small (in which case at any one time the entire program will be in memory), the process running this program uses only a few segments of the program, each segment mapped onto its own memory page. Therefore, only a few memory pages are needed—generally fewer than the program's size might imply.
When a process needs an additional program segment to be loaded into memory, it asks the system whether the page containing this segment is already loaded. If the page is not found, an event known as a "page fault" occurs. This requires the system to allocate a free memory page, go to the disk, and finally read and load the requested segment into the allocated memory page.
If a process needs to bring a new page into physical memory and there are no free physical pages available, the operating system must make room for this page by discarding another page from physical memory.
If the page to be discarded from physical memory came from a binary image or data file and has not been modified, the page does not need to be saved. Instead, it can be discarded, and if the process needs that page again it can be brought back into memory from the image or data file.
However, if the page has been modified, the operating system must preserve the contents of that page so that it can be accessed at a later time. This type of page is known as a dirty page, and when it is removed from memory it is saved in a special sort of file called the swap file. This process is referred to as swapping out.
Accesses to the swap file are very slow compared with the speed of the processor and physical memory, and the operating system must juggle the need to write pages to disk with the need to retain them in memory to be used again.
To try to reduce the probability that a page will be needed just after it has been swapped out, the system may use the LRU (least recently used) algorithm or some similar algorithm.
To summarize the two swapping scenarios, discarding read-only pages incurs little overhead compared with discarding data pages that have been modified, since in the latter case the pages have to be written to a swap partition located on the (very slow) disk. Thus, the fewer memory pages there are that can become dirty, the better will be the machine's overall performance.
But in Perl, both the program code and the program data are seen as data pages by the OS. Both are mapped to the same memory pages. Therefore, a big chunk of Perl code can become dirty when its variables are modified, and when those pages need to be discarded they have to be written to the swap partition.
This leads us to two important conclusions about swapping and Perl:
Running the system when there is no free physical memory available hinders performance, because processes' memory pages will be discarded and then reread from disk again and again.
Since the majority of the running code is Perl code, in addition to the overhead of reading in the previously discarded pages, there is the additional overhead of saving the dirty pages to the swap partition.
When the system has to swap memory pages in and out, it slows down. This can lead to an accumulation of processes waiting for their turn to run, which further increases processing demands, which in turn slows down the system even more as more memory is required. Unless the resource demand drops and allows the processes to catch up with their tasks and go back to normal memory usage, this ever-worsening spiral can cause the machine to thrash the disk and ultimately to halt.
In addition, it is important to be aware that for better performance, many programs (particularly programs written in Perl) do not return memory pages to the operating system even when they are no longer needed. If some of the memory is freed, it is reused when needed by the process itself, without creating the additional overhead of asking the system to allocate new memory pages. That is why Perl programs tend to grow in size as they run and almost never shrink.
When the process quits, it returns all the memory pages it used to the pool of available pages for other processes to use.
It should now be obvious that a system that runs a web server should never swap. Of course, it is quite normal for a desktop machine to swap, and this is often apparent because everything slows down and sometimes the system starts freezing for short periods. On a personal machine, the solution to swapping is simple: do not start up any new programs for a minute, and try to close down any that are running unnecessarily. This will allow the system to catch up with the load and go back to using just RAM. Unfortunately, this solution cannot be applied to a web server.
In the case of a web server, we have much less control, since it is the remote users who load the machine by issuing requests to the server. Therefore, the server should be configured such that the maximum number of possible processes will be small enough for the system to handle. This is achieved with the MaxClients directive, discussed in Chapter 11. This will ensure that at peak times, the system will not swap. Remember that for a web server, swap space is an emergency pool, not a resource to be used routinely. If the system is low on memory, either buy more memory or reduce the number of processes to prevent swapping, as discussed in Chapter 14.
However, due to faulty code, sometimes a process might start running in an infinite loop, consuming all the available RAM and using lots of swap memory. In such a situation, it helps if there is a big emergency pool (i.e., lots of swap memory). But the problem must still be resolved as soon as possible, since the pool will not last for long. One solution is to use the Apache::Resource module, described in the next section.
There are times when we need to prevent processes from excessive consumption of system resources. This includes limiting CPU or memory usage, the number of files that can be opened, and more.
The Apache::Resource module uses the BSD::Resource module, which in turn uses the C function setrlimit( ) to set limits on system resources.
A resource limit is specified in terms of a soft limit and a hard limit. When a soft limit (for example, CPU time or file size) is exceeded, the process may receive a signal, but it will be allowed to continue execution until it reaches the hard limit (or modifies its resource limit). The rlimitstructure is used to specify the hard and soft limits on a resource. (See the setrlimit manpage for OS-specific information.)
If the value of variable in rlimit is of the form S:H, S is treated as the soft limit, and H is the hard limit. If the value is a single number, it is used for both soft and hard limits. So if the value is 10:20, the soft limit is 10 and the hard limit is 20, whereas if the value is just 20, both the soft and the hard limits are set to 20.
The most common use of this module is to limit CPU usage. The environment variable PERL_RLIMIT_CPU defines the maximum amount of CPU time the process can use. If it attempts to run longer than this amount, it is killed, no matter what it is doing at the time, be it processing a request or just waiting. This is very useful when there is a bug in the code and a process starts to spin in an infinite loop, using a lot of CPU resources and never completing the request.
The value is measured in seconds. The following example sets the soft limit for CPU usage to 120 seconds (the default is 360):
PerlModule Apache::Resource PerlSetEnv PERL_RLIMIT_CPU 120
Although 120 seconds does not sound like a long time, it represents a great deal of work for a modern processor capable of millions of instructions per second. Furthermore, because the child process shares the CPU with other processes, it may be quite some time before it uses all its allotted CPU time, and in all probability it will die from other causes (for example, it may have served all the requests it is permitted to serve before this hard limit is reached).
Of course, we should tell mod_perl to use this module, which is done by adding the following directive to httpd.conf:
PerlChildInitHandler Apache::Resource
There are other resources that we might want to limit. For example, we can limit the data and bstack memory segment sizes (PERL_RLIMIT_DATA and PERL_RLIMIT_STACK), the maximum process file size (PERL_RLIMIT_FSIZE), the core file size (PERL_RLIMIT_CORE), the address space (virtual memory) limit (PERL_RLIMIT_AS), etc. Refer to the setrlimit manpage for other possible resources. Remember to prepend PERL_ to the resource types that are listed in the manpage.
If Apache::Status is configured, it can display the resources set in this way. Remember that Apache::Status must be loaded before Apache::Resource, in order to enable the resources display menu.
To turn on debug mode, set the $Apache::Resource::Debug variable before loading the module. This can be done using a Perl section in httpd.conf.
<Perl>
$Apache::Resource::Debug = 1;
require Apache::Resource;
</Perl>
PerlChildInitHandler Apache::ResourceNow view the error_log file using tail -f and watch the debug messages show up when requests are served.
Under certain Linux setups, malloc( ) uses mmap( ) instead of brk( ). This is done to conserve virtual memory—that is, when a program malloc( )s a large block of memory, the block is not actually returned to the program until it is initialized. The old-style brk( )system call obeyed resource limits on data segment sizes as set in setrlimit( ). mmap( ) does not.
Apache::Resource's defaults put limits on data size and stack size. Linux's current memory-allocation scheme does not honor these limits, so if we just do:
PerlSetEnv PERL_RLIMIT_DEFAULTS On PerlModule Apache::Resource PerlChildInitHandler Apache::Resource
our Apache processes are still free to use as much memory as they like.
However, BSD::Resource also has a limit called RLIMIT_AS (Address Space), which limits the total number of bytes of virtual memory assigned to a process. Fortunately, Linux's memory manager does honor this limit.
Therefore, we can limit memory usage under Linux with Apache::Resource. Simply add a line to httpd.conf:
PerlSetEnv PERL_RLIMIT_AS 67108864
This example sets hard and soft limits of 64 MB of total address space.
Refer to the Apache::Resource and setrlimit(2) manpages for more information.
Generally, limits should be imposed on mod_perl processes to prevent mayhem if something goes wrong. There is no need to limit processes if the code does not have any bugs, or at least if there is sufficient confidence that the program will never overconsume resources. When there is a risk that a process might hang or start consuming a lot of memory, CPU, or other resources, it is wise to use the Apache::Resource module.
But what happens if a process is stuck waiting for some event to occur? Consider a process trying to acquire a lock on a file that can never be satisfied because there is a deadlock. The process just hangs waiting, which means that neither extra CPU nor extra memory is used. We cannot detect and terminate this process using the resource-limiting techniques we just discussed. If there is such a process, it is likely that very soon there will be many more processes stuck waiting for the same or a different event to occur. Within a short time, all processes will be stuck and no new processes will be spawned because the maximum number, as specified by the MaxClients directive, has been reached. The service enters a state where it is up but not serving clients.
If a watchdog is run that does not just check that the process is up, but actually issues requests to make sure that the service responds, then there is some protection against a complete service outage. This is because the watchdog will restart the server if the testing request it issues times out. This is a last-resort solution; the ideal is to be able to detect and terminate hanging processes that do not consume many resources (and therefore cannot be detected by the Apache::Resource module) as soon as possible, not when the service stops responding to requests, since by that point the quality of service to the users will have been severely degraded.
This is where the Apache::Watchdog::RunAway module comes in handy. This module samples all live child processes every $Apache::Watchdog::RunAway::POLLTIMEseconds. If a process has been serving the same request for more than $Apache::Watchdog::RunAway::TIMEOUTseconds, it is killed.
To perform accounting, the Apache::Watchdog::RunAway module uses the Apache::Scoreboard module, which in turn delivers various items of information about live child processes. Therefore, the following configuration must be added to httpd.conf:
<Location /scoreboard>
SetHandler perl-script
PerlHandler Apache::Scoreboard::send
order deny,allow
deny from all
allow from localhost
</Location>Make sure to adapt the access permission to the local environment. The above configuration allows access to this handler only from the localhostserver. This setting can be tested by issuing a request for http://localhost/scoreboard. However, the returned data cannot be read directly, since it uses a binary format.
We are now ready to configure Apache::Watchdog::RunAway. The module should be able to retrieve the information provided by Apache::Scoreboard, so we will tell it the URL to use:
$Apache::Watchdog::RunAway::SCOREBOARD_URL = "http://localhost/scoreboard";
We must decide how many seconds the process is allowed to be busy serving the same request before it is considered a runaway. Consider the slowest clients. Scripts that do file uploading and downloading might take a significantly longer time than normal mod_perl code.
$Apache::Watchdog::RunAway::TIMEOUT = 180; # 3 minutes
Setting the timeout to 0 will disable the Apache::Watchdog::RunAway module entirely.
The rate at which the module polls the server should be chosen carefully. Because of the overhead of fetching the scoreboard data, this is not a module that should be executed too frequently. If the timeout is set to a few minutes, sampling every one or two minutes is a good choice. The following directive specifies the polling interval:
$Apache::Watchdog::RunAway::POLLTIME = 60; # 1 minute
Just like the timeout value, polling time is measured in seconds.
To see what the module does, enable debug mode:
$Apache::Watchdog::RunAway::DEBUG = 1;
and watch its log file using the tail command.
The following statement allows us to specify the log file's location:
$Apache::Watchdog::RunAway::LOG_FILE = "/tmp/safehang.log";
This log file is also used for logging information about killed processes, regardless of the value of the $DEBUG variable.
The module uses a lock file in order to prevent starting more than one instance of itself. The default location of this file may be changed using the $LOCK_FILE variable.
$Apache::Watchdog::RunAway::LOCK_FILE = "/tmp/safehang.lock";
There are two ways to invoke this process: using the Perl functions, or using the bundled utility called amprapmon (mnemonic: ApacheModPerlRunAwayProcessMonitor).
The following functions are available:
In order for mod_perl to invoke this process, all that is needed is the start_detached_monitor( ) function. Add the following code to startup.pl:
use Apache::Watchdog::RunAway( ); Apache::Watchdog::RunAway::start_detached_monitor( );
Another approach is to use the amprapmon utility. This can be started from the startup.pl file:
system "amprapmon start";
This will fork a new process. If the process is already running, it will just continue to run.
The amprapmon utility could instead be started from cron or from the command line.
No matter which approach is used, the process will fork itself and run as a daemon process. To stop the daemon, use the following command:
panic% amprapmon stop
If we want to test this module but have no code that makes processes hang (or we do, but the behavior is not reproducible on demand), the following code can be used to make the process hang in an infinite loop when executed as a script or handler. The code writes "\0" characters to the browser every second, so the request will never time out. The code is shown in Example 5-12.
my $r = shift;
$r->send_http_header('text/plain');
print "PID = $$\n";
$r->rflush;
while(1) {
$r->print("\0");
$r->rflush;
sleep 1;
}The code prints the PID of the process running it before it goes into an infinite loop, so that we know which process hangs and whether it gets killed by the Apache::Watchdog::RunAway daemon as it should.
Of course, the watchdog is used only for prevention. If you have a serious problem with hanging processes, you have to debug your code, find the reason for the problem, and resolve it, as discussed in Chapter 21.
To limit the number of Apache children that can simultaneously serve a specific resource, take a look at the Apache mod_throttle_access module.
Throttling access is useful, for example, when a handler uses a resource that places a limitation on concurrent access or that is very CPU-intensive. mod_throttle_access limits the number of concurrent requests to a given URI.
Consider a service providing the following three URIs:
/perl/news/ /perl/webmail/ /perl/morphing/
The response times of the first two URIs are critical, since people want to read the news and their email interactively. The third URI is a very CPU- and RAM-intensive image-morphing service, provided as a bonus to the users. Since we do not want users to abuse this service, we have to set some limit on the number of concurrent requests for this resource. If we do not, the other two critical resources may have their performance degraded.
When compiled or loaded into Apache and enabled, mod_throttle_access makes the MaxConcurrentReqs directive available. For example, the following setting:
<Location "/perl/morphing">
<Limit PUT GET POST>
MaxConcurrentReqs 10
</Limit>
</Location>will allow only 10 concurrent PUT, GET, HEAD (as implied by GET), or POST requests for the URI /perl/morphing to be processed at any given time. The other two URIs in our example remain unlimited.
Web services generally welcome search engine robots, also called spiders. Search engine robots are programs that query the site and index its documents for a search engine.
Most indexing robots are polite and pause between requests. However, some search engine robots behave very badly, issuing too many requests too often, thus slowing down the service for human users. While everybody wants their sites to be indexed by search engines, it is really annoying when an initially welcomed spider gives the server a hard time, eventually becoming an unwanted spider.
A common remedy for keeping impolite robots off a site is based on an AccessHandler that checks the name of the robot and disallows access to the server if it is listed in the robot blacklist. For an example of such an AccessHandler, see the Apache::BlockAgent module, available from http://www.modperl.com/.
Unfortunately, some robots have learned to work around this blocking technique, masquerading as human users by using user agent strings identifying them as conventional browsers. This prevents us from blocking just by looking at the robot's name—we have to be more sophisticated and beat the robots by turning their own behavior against them. Robots work much faster than humans, so we can gather statistics over a period of time, and when we detect too many requests issued too fast from a specific IP, this IP can be blocked.
The Apache::SpeedLimit module, also available from http://www.modperl.com/, provides this advanced filtering technique.
There might be a problem with proxy servers, however, where many users browse the Web via a single proxy. These users are seen from the outside world (and from our sites) as coming from the proxy's single IP address or from one of a small set of IP addresses. In this case, Apache::SpeedLimit cannot be used, since it might block legitimate users and not just robots. However, we could modify the module to ignore specific IP addresses that we designate as acceptable.
Stonehenge::Throttle
Randal Schwartz wrote Stonehenge::Throttle for one of his Linux Magazine columns. This module does CPU percentage-based throttling. The module looks at the recent CPU usage over a given window for a given IP. If the percentage exceeds a threshold, a 503 error and a correct Retry-After: header are sent, telling for how long access from this IP is banned. The documentation can be found at http://www.stonehenge.com/merlyn/LinuxMag/col17.html, and the source code is available at http://www.stonehenge.com/merlyn/LinuxMag/col17.listing.txt.
Spambot Trap
Neil Gunton has developed a Spambot Trap (http://www.neilgunton.com/spambot_trap/) that keeps robots harvesting email addresses away from your web content. One of the important components of the trap is the robots.txt file, which is a standard mechanism for controlling which agents can reach your site and which areas can be browsed. This is an advisory mechanism, so if the agent doesn't follow the standard it will simply ignore the rules of the house listed in this file. For more information, refer to the W3C specification at http://www.w3.org/TR/html401/appendix/notes.html#h-B.4.1.1.
|  | |
| 5.10. Web Server Monitoring |  | 5.12. References |

Copyright © 2003 O'Reilly & Associates. All rights reserved.