 |  |

| |
What's New in Apache 2.0
What's New in Perl 5.6.0-5.8.0
What's New in mod_perl 2.0
Installing mod_perl 2.0
Configuring mod_perl 2.0
Resources
Since Doug MacEachern introduced mod_perl 1.0[58] in 1996, he has had to tweak it with every change in Apache and Perl, while maintaining compatibility with the older versions. These rewrites have led to very complex source code, with hundreds of #ifdefs and workarounds for various incompatibilities in older Perl and Apache versions.
[58]Here and in the rest of this and the next chapter we refer to the mod_perl 1.x series as mod_perl 1.0 and to 2.0.x as mod_perl 2.0 to keep things simple. Similarly, we call the Apache 1.3.x series Apache 1.3 and the 2.0.x series Apache 2.0.
Apache 2.0, however, is based on a new threads design, requiring that mod_perl be based on a thread-safe Perl interpreter. Perl 5.6.0 was the first Perl version to support internal thread-safety across multiple interpreters. Since Perl 5.6.0 and Apache 2.0 are the very minimum requirements for the newest version of mod_perl, backward compatibility was no longer a concern, so this seemed like a good time to start from scratch. mod_perl 2.0 was the result: a leaner, more efficient mod_perl that's streamlined for Apache 2.0.
mod_perl 2.0 includes a mechanism for building the Perl interface to the Apache API automatically, allowing us to easily adjust mod_perl 2.0 to the ever-changing Apache 2.0 API during its development period. Another important feature is the Apache::Test framework, which was originally developed for mod_perl 2.0 but then was adopted by Apache 2.0 developers to test the core server features and third-party modules. Moreover the tests written using the Apache::Test framework could be run with Apache 1.0 and 2.0, assuming that both supported the same features.
Many other interesting changes have already happened to mod_perl in Version 2.0, and more will be developed in the future. Some of these will be covered in this chapter, and some you will discover on your own while reading mod_perl documentation.
At the time of this writing, mod_perl 2.0 is considered beta when used with the prefork Multi-Processing Model module (MPM) and alpha when used with a threaded MPM. It is likely that Perl 5.8.0+ will be required for mod_perl 2.0 to move past alpha with threaded MPMs. Also, the Apache 2.0 API hasn't yet been finalized, so it's possible that certain examples in this chapter may require modifications once production versions of Apache 2.0 and mod_perl 2.0 are released.
In this chapter, we'll first discuss the new features in Apache 2.0, Perl 5.6 and later, and mod_perl 2.0 (in that order). Then we'll cover the installation and configuration of mod_perl 2.0. Details on the new functionality implemented in mod_perl 2.0 are provided in Chapter 25.
Whereas Apache 1.2 and 1.3 were based on the NCSA httpd code base, Apache 2.0 rewrote big chunks of the 1.3 code base, mainly to support numerous new features and enhancements. Here are the most important new features:
The APR uses the concept of memory pools, which significantly simplifies the memory-management code and reduces the possibility of memory leaks (which always haunt C programmers).
With I/O filtering in place, simple filters (e.g., data compression and decompression) can easily be implemented, and complex filters (e.g., SSL) can now be implemented without needing to modify the the server code (unlike with Apache 1.3).
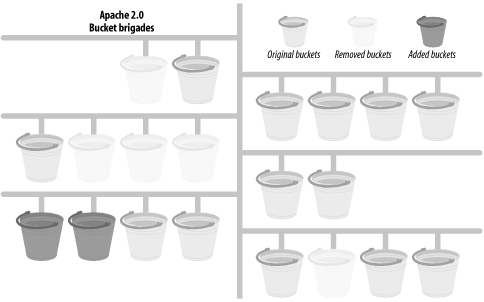
To make the filtering mechanism efficient and avoid unnecessary copying, the bucket brigades model was used, as follows.
A bucket represents a chunk of data. Buckets linked together comprise a brigade. Each bucket in a brigade can be modified, removed, and replaced with another bucket. The goal is to minimize the data copying where possible. Buckets come in different types: files, data blocks, end-of-stream indicators, pools, etc. You don't need to know anything about the internal representation of a bucket in order to manipulate it.
The stream of data is represented by bucket brigades. When a filter is called, it gets passed the brigade that was the output of the previous filter. This brigade is then manipulated by the filter (e.g., by modifying some buckets) and passed to the next filter in the stack.
Figure 24-1 depicts an imaginary bucket brigade. The figure shows that after the presented bucket brigade has passed through several filters, some buckets were removed, some were modified, and some were added. Of course, the handler that gets the brigade doesn't know the history of the brigade; it can only see the existing buckets in the brigade. We will see bucket brigades in use when discussing protocol handlers and filters.
Apache 2.0 introduces the concept of MPMs, whose main responsibility is to map the incoming requests to either threads, processes, or a threads/processes hybrid. Now it's possible to write different processing modules specific to various platforms. For example, Apache 2.0 on Windows is much more efficient and maintainable now, since it uses mpm_winnt, which deploys native Windows features.
Here is a partial list of the major MPMs available as of this writing:
On platforms that support more than one MPM, it's possible to switch the used MPMs as the need changes. For example, on Unix it's possible to start with a preforked module, then migrate to a more efficient threaded MPM as demand grows and the code matures (assuming that the code base is capable of running in the threaded environment).
All these new features boost Apache's performance, scalability, and flexibility. The APR helps the overall performance by doing lots of platform-specific optimizations in the APR internals and giving the developer the already greatly optimized API.
The I/O layering helps performance too, since now modules don't need to waste memory and CPU cycles to manually store the data in shared memory or pnotes in order to pass the data to another module (e.g., to provide gzip compression for outgoing data).
And, of course, an important impact of these features is the simplification and added flexibility for the core and third-party Apache module developers.
|  | |
| V. mod_perl 2.0 |  | 24.2. What's New in Perl 5.6.0-5.8.0 |

Copyright © 2003 O'Reilly & Associates. All rights reserved.