
 |  |
7.6. Keeping Everything Running Smoothly
A significant part of maintenance is being aware that something is wrong before it becomes a real problem. If you catch a problem early, chances are it'll be that much easier to fix. As the old adage says, an ounce of prevention is worth a pound of cure.This isn't quite troubleshooting -- we'll devote an entire chapter to troubleshooting later -- think of it more as "pre-troubleshooting." Troubleshooting (the pound of cure) is what you have to do after your problem has developed complications, and then you need to identify the problem by its symptoms.
The next two sections deal with preventative maintenance: looking periodically at the syslog file and at the BIND name server statistics to see whether any problems are developing. Consider this a name server's medical checkup.
7.6.1. Common Syslog Messages
There are a large number of syslog messages that named can emit. In practice, you'll see only a few of them. We'll cover the most common syslog messages here, excluding reports of syntax errors in zone data files.Every time you start named, it sends out a message at priority LOG_NOTICE. For a BIND 8 name server, it looks like this:
For BIND 9, it's significantly abridged:Jan 10 20:48:32 terminator named[3221]: starting. named 8.2.3 Tue May 16 09:39:40 MDT 2000 ^Icricket@huskymo.boulder.acmebw.com:/usr/local/src/bind-8.2.3/src/bin/ named
This message logs the fact that named started at this time and tells you the version of BIND you're running as well as who built it and where (for BIND 8). Of course, this is nothing to be concerned about. It is a good place to look if you're not sure what version of BIND your operating system supports. (Older versions of BIND used the message "restarted" instead of "starting.")Jul 27 16:18:41 terminator named[7045]: starting BIND 9.1.0
Every time you send the name server a reload command, a BIND 8 name server sends out this message at priority LOG_NOTICE:
BIND 9 name servers log:Jan 10 20:50:16 terminator named[3221]: reloading nameserver
These messages simply tell you that named reloaded its database (as a result of a reload command) at this time. Again, this is nothing to be concerned about. This message will most likely be of interest when you are tracking down how long a bad resource record has been in your zone data or how long a whole zone has been missing because of a mistake during an update.Jul 27 16:27:45 terminator named[7047]: loading configuration from '/etc/named.conf
Another message you may see shortly after your name server starts is:
Jan 10 20:50:20 terminator named[3221]: cannot set resource limits on
this systemIf you run your name server on a host with many network interfaces (especially virtual network interfaces), you may see this message soon after startup or even after your name server has run well for a while:
Jan 10 20:50:31 terminator named[3221]: fcntl(dfd, F_DUPFD, 20): Too
many open files
Jan 10 20:50:31 terminator named[3221]: fcntl(sfd, F_DUPFD, 20): Too
many open filesThe next step is either to get BIND to use fewer file descriptors, or to raise the limit the operating system places on the number of file descriptors BIND can use:
- If you don't need BIND listening on all your network interfaces (particularly the virtual ones), use the listen-on substatement to configure BIND to listen only on those interfaces it needs to. See Chapter 10, "Advanced Features" for details on the syntax of listen-on.
- If your operating system supports getrlimit( ) and setrlimit( ) (as just described), configure your name server to use a larger number of files with the files substatement. See Chapter 10, "Advanced Features" for details on using the files substatement.
- If your operating system places too restrictive a limit on open files, raise that limit before you start named with the ulimit command.
Jan 10 21:49:50 terminator named[3221]: master zone "movie.edu" (IN)
Loaded (serial 1996011000)About every hour, a BIND 8 name server sends a snapshot of the current statistics at priority LOG_INFO:
Feb 18 14:09:02 terminator named[3565]: USAGE 824681342 824600158
CPU=13.01u/3.26s CHILDCPU=9.99u/12.71s
Feb 18 14:09:02 terminator named[3565]: NSTATS 824681342 824600158
A=4 PTR=2
Feb 18 14:09:02 terminator named[3565]: XSTATS 824681342 824600158
RQ=6 RR=2 RIQ=0 RNXD=0 RFwdQ=0 RFwdR=0 RDupQ=0 RDupR=0
RFail=0 RFErr=0 RErr=0 RTCP=0 RAXFR=0 RLame=0 Ropts=0
SSysQ=2 SAns=6 SFwdQ=0 SFwdR=0 SDupQ=5 SFail=0 SFErr=0
SErr=0 RNotNsQ=6 SNaAns=2 SNXD=1If BIND Version 4.9.4 or later (but not BIND 9 as of 9.1.0 -- it doesn't implement name checking yet) finds a name that doesn't conform to RFC 952, it logs a syslog error:
Jul 24 20:56:26 terminator named[1496]: owner name "ID_4.movie.edu IN"
(primary) is invalid - rejectingAnother syslog message, sent at priority LOG_INFO, is a warning message about the zone data:
Jan 10 20:48:38 terminator named[3221]: terminator2 has CNAME
and other data (invalid)
The MX record for terminator2 is incorrect and would cause the message just listed. terminator2is an alias for t2, which is the canonical name. As described earlier, when a name server looks up a name and finds a CNAME, it replaces the original name with the canonical name, and then tries looking up the canonical name. Thus, when the server looks up the MX data for terminator2, it finds a CNAME record and then looks up the MX record for t2. Since the server follows the CNAME record for terminator2, it never uses the MX record for terminator2; in fact, this record is illegal. In other words, all resource records for a host have to use the canonical name; it's an error to use an alias in place of the canonical name.terminator2 IN CNAME t2 terminator2 IN MX 10 t2 t2 IN A 192.249.249.10 t2 IN MX 10 t2
We realize this is getting repetitive, but BIND 9 doesn't detect this error until 9.1.0.
The following message indicates that a BIND 4 or 8 slave was unable to reach any master server when it tried to do a zone transfer:
Jan 10 20:52:42 wormhole named[2813]: zoneref: Masters for
secondary zone "movie.edu" unreachable
This message is sent at priority LOG_NOTICE on BIND 4 or 8, and LOG_INFO on BIND 9, and is sent only the first time the zone transfer fails. When the zone transfer finally succeeds, a 4.9 or later name server tells you that the zone transferred by issuing another syslog message. Older servers don't tell you when the zone transferred. When this message first appears, you don't need to take any immediate action. The name server will continue to attempt to transfer the zone according to the retry period in the SOA record. After a few days (or half the expire time), you might check that the server was able to transfer the zone. On servers that don't issue the syslog message when the zone transfers, you can verify that the zone transferred by checking the timestamp on the backup zone data file. When a zone transfer succeeds, a new backup file is created. When a name server finds a zone is up to date, it "touches" the backup file (à la the Unix touch command). In both cases, the timestamp on the backup file is updated, so go to the slave and give the command ls -l /usr/local/named/db*. This will tell you when the slave last synchronized each zone with the master server. We'll cover how to troubleshoot slaves failing to transfer zones in Chapter 14, "Troubleshooting DNS and BIND".Jul 27 16:50:55 terminator named[7174]: refresh_callback: zone movie.edu/IN: failure for 10.0.0.1#53: timed out
If you are watching the syslog messages on your 4.9 or later master name server, you'll see a LOG_INFO syslog message when the slave picks up the new zone data or when a tool such as nslookup transfers a zone:
Mar 7 07:30:04 terminator named[3977]: approved AXFR from
[192.249.249.1].2253 for "movie.edu"If you're using the BIND 4 xfrnets configuration file directive or BIND 8 allow-transfer substatement (explained in Chapter 10, "Advanced Features") to limit which servers can load zones, you may see this message saying unapproved instead of approved. A BIND 9 name server reports:
You'd see this syslog message only if you capture LOG_INFO syslog messages:Jul 27 16:59:26 terminator named[7174]: client 192.249.249.1#1386: zone transfer denied
Jan 10 20:52:42 wormhole named[2813]: Malformed response
from 192.1.1.1A BIND 4.9 or 8 named logs this message when you try to sneak records into your zone data file that belong in another zone:
Jun 13 08:02:03 terminator named[2657]: db.movie.edu:28: data "foo.bar.edu"
outside zone "movie.edu" (ignored)
For instance, if we tried to use this zone data:Jul 27 17:07:01 terminator named[7174]: dns_master_load: db.movie.edu:28: ignoring out-of-zone data
we'd be adding data for the bar.edu zone into our movie.edu zone data file. A 4.8.3 vintage name server would blindly add foo.bar.edu to its cache, and wouldn't check that all the data in the db.movie.edu file was in the movie.edu zone. You can't fool a name server newer than 4.9, though. This syslog message is logged at priority LOG_INFO.robocop IN A 192.249.249.2 terminator IN A 192.249.249.3 ; Add this entry to the name server's cache foo.bar.edu. IN A 10.0.7.13
Earlier in the book, we said that you couldn't use a CNAME in the data portion of a resource record. BIND Versions 4.9 and 8 will catch this misuse:
Jun 13 08:21:04 terminator named[2699]: "movie.edu IN NS" points to a
CNAME (dh.movie.edu)Here is an example of the offending resource records:
@ NS terminator.movie.edu.
NS dh.movie.edu.
terminator.movie.edu. IN A 192.249.249.3
diehard.movie.edu. IN A 192.249.249.4
dh IN CNAME diehardTIP: You'll only see the syslog message when the offending data is looked up. This syslog message is logged by a BIND 4.9.3 or BIND 8 server at priority LOG_INFO, and by a 4.9.4 to 4.9.7 server at priority LOG_DEBUG.The following message indicates that your name server may be guarding itself against one type of network attack:
Jun 11 11:40:54 terminator named[131]: Response from unexpected source
([204.138.114.3].53)Less paranoid admins will realize that this situation can also happen if a parent zone's name server knows about only one of the IP addresses of a multihomed name server for a child zone. The parent tells your name server the one IP address it knows about, and when your server queries the remote name server, the remote name server responds from the other IP address. This shouldn't happen if BIND is running on the remote name server host, because BIND makes every effort to use the same IP address in the response as the query was sent to. This syslog message is logged at priority LOG_INFO.
Here's an interesting syslog message:
Jun 10 07:57:28 terminator named[131]: No root nameservers for
class 226This message might appear if you are backing up some other zone:
Jun 7 20:14:26 wormhole named[29618]: Zone "253.253.192.in-addr.arpa"
(class 1) SOA serial# (3345) rcvd from [192.249.249.10]
is < ours (563319491)By the way, if that pesky admin was running a BIND 8 or 9 name server, then he must have missed (or ignored) a message his server logged, telling him that he'd rolled the zone's serial number back. On a BIND 8 name server, the message looks like:
Jun 7 19:35:14 terminator named[3221]: WARNING: new serial number < old
(zp->z_serial < serial)
This message is logged at LOG_NOTICE.Jun 7 19:36:41 terminator named[9832]: dns_zone_load: zone movie.edu/IN: zone serial has gone backwards
You might want to remind him of the wisdom of checking syslog after making any changes to the name server.
This BIND 8 message will undoubtedly become familiar to you:
Aug 21 00:59:06 terminator named[12620]: Lame server on 'foo.movie.edu'
(in 'MOVIE.EDU'?): [10.0.7.125].53 'NS.HOLLYWOOD.LA.CA.US':
learnt (A=10.47.3.62,NS=10.47.3.62)
"Aye, Captain, she's sucking mud!" There's some mud out there in the Internet waters in the form of bad delegations. A parent name server is delegating a subdomain to a child name server, and the child name server is not authoritative for the subdomain. In this case, the edu name server is delegating movie.edu to 10.0.7.125, and the name server on this host is not authoritative for movie.edu. Unless you know the admin for movie.edu, there's probably nothing you can do about this. The syslog message is logged by a 4.9.3 server at priority LOG_WARNING, by a 4.9.4 to 4.9.7 server at priority LOG_DEBUG, and by a BIND 8 or 9 server at LOG_INFO.Jan 15 10:20:16 terminator named[14205]: lame server on 'foo.movie.edu' (in 'movie.EDU'?): 10.0.7.125#53
If your BIND 4.9 or later name server's configuration file has:
or your BIND 8 or 9 configuration file has:options query-log
logging { category queries { default_syslog; }; };
Feb 20 21:43:25 terminator named[3830]:
XX /192.253.253.2/carrie.movie.edu/A
Feb 20 21:43:32 terminator named[3830]:
XX /192.253.253.2/4.253.253.192.in-addr.arpa/PTR
These messages include the IP address of the host that made the query as well as the query itself. On a BIND 8.2.1 or later name server, recursive queries are marked with XX+ instead of XX. Make sure you have lots of disk space if you log all the queries to a busy name server. (On a running server, you can toggle query logging on and off with the querylog command.)Jan 13 18:32:25 terminator named[13976]: client 192.253.253.2#1702: query: carrie. movie.edu IN A Jan 13 18:32:42 terminator named[13976]: client 192.253.253.2#1702: query: 4.253. 253.192.in-addr.arpa IN PTR
Starting with BIND 8.1.2, you might see this set of syslog messages:
May 19 11:06:08 named[21160]: bind(dfd=20, [10.0.0.1].53):
Address already in use
May 19 11:06:08 named[21160]: deleting interface [10.0.0.1].53
May 19 11:06:08 named[21160]: bind(dfd=20, [127.0.0.1].53):
Address already in use
May 19 11:06:08 named[21160]: deleting interface [127.0.0.1].53
May 19 11:06:08 named[21160]: not listening on any interfaces
May 19 11:06:08 named[21160]: Forwarding source address
is [0.0.0.0].1835
May 19 11:06:08 named[21161]: Ready to answer queries.
What has happened is that you had a name server running and you started up a second name server without killing the first one. Unlike what you might expect, the second name server continues to run; it just isn't listening on any interfaces.Jul 27 17:15:58 terminator named[7357]: listening on IPv4 interface lo, 127.0.0.1#53 Jul 27 17:15:58 terminator named[7357]: binding TCP socket: address in use Jul 27 17:15:58 terminator named[7357]: listening on IPv4 interface eth0, 206.168.194.122#53 Jul 27 17:15:58 terminator named[7357]: binding TCP socket: address in use Jul 27 17:15:58 terminator named[7357]: listening on IPv4 interface eth1, 206.168.194.123#53 Jul 27 17:15:58 terminator named[7357]: binding TCP socket: address in use Jul 27 17:15:58 terminator named[7357]: couldn't add command channel 0.0.0.0#953: address in use
7.6.2. Understanding the BIND Statistics
Periodically, you should look over the statistics on some of your name servers, if only to see how busy they are. We'll now show you an example of the name server statistics and discuss what each line means. Name servers handle many queries and responses during normal operation, so first we need to show you what a typical exchange might look like.Reading the explanations for the statistics is hard without a mental picture of what goes on during a lookup. To help you understand the name server's statistics, Figure 7-2 shows what might happen when an application tries to look up a domain name. The application, FTP, queries a local name server. The local name server had previously looked up data in this zone and knows where the remote name servers are. It queries each of the remote name servers -- one of them twice -- trying to find the answer. In the meantime, the application times out and sends yet another query, asking for the same information.
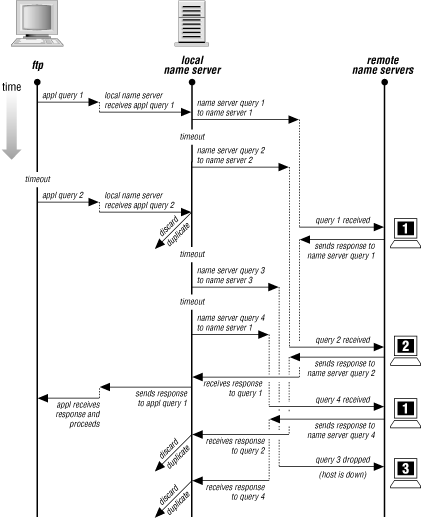
Figure 7-2. Example query/response exchange
Keep in mind that even though a name server has sent a query to a remote name server, the remote name server may not receive the query right away. The query might be delayed or lost by the underlying network, or perhaps the remote name server host might be busy with another application.Notice that a BIND name server is able to detect duplicate queries only while it is still trying to answer the original query. The local name server detects the duplicate query from the application because the local name server is still working on it. But remote name server 1 does not detect the duplicate query from the local name server because it answered the previous query. After the local name server receives the first response from remote name server 1, all other responses are discarded as duplicates. This dialog required the following exchanges:
| Exchange | Number |
|---|---|
| Application to local name server | 2 queries |
| Local name server to application | 1 response |
| Local name server to remote name server 1 | 2 queries |
| Remote name server 1 to local name server | 2 responses |
| Local name server to remote name server 2 | 1 query |
| Remote name server 2 to local name server | 1 response |
| Local name server to remote name server 3 | 1 query |
| Remote name server 3 to local name server | 0 responses |
These exchanges would make the following contributions to the local name server's statistics:
| Statistic | Cause |
|---|---|
| 2 queries received | From the application on the local host |
| 1 duplicate query | From the application on the local host |
| 1 answer sent | To the application on the local host |
| 3 responses received | From remote name servers |
| 2 duplicate responses | From remote name servers |
| 2 A queries | Queries for address information |
In our example, the local name server received queries only from an application, yet it sent queries to remote name servers. Normally, the local name server would also receive queries from remote name servers (that is, in addition to asking remote servers for information it needs to know, the local server would also be asked by remote servers for information they need to know), but we didn't show any remote queries for the sake of simplicity.
7.6.2.1. BIND 4.9 and 8 statistics
Now that you've seen a typical exchange between applications and name servers, as well as the statistics it generated, let's go over a more extensive example of the statistics. To get the statistics from your BIND 8 name server, use ndc:
On older BIND 4 name servers without ndc, send named the ABRT signal:# ndc stats
(The process ID is stored in /etc/named.pid on pre-SVR4 filesystems.) Wait a few seconds and look at the file named.stats in the name server's working directory (for BIND 8) or at /var/tmp/named.stats or /usr/tmp/named.stats (for BIND 4). If the statistics are not dumped to this file, your server may not have been compiled with STATS defined and, thus, may not be collecting statistics. Following are the statistics from one of Paul Vixie's BIND 4.9.3 name servers. BIND 8 name servers have all of the same items listed here except for RnotNsQ, and the items are arranged in a different order. BIND 9 name servers, as of 9.1.0, keep an entirely different set of statistics, which we'll show you in the next section.# kill -ABRT `cat /var/run/named.pid`
+++ Statistics Dump +++ (800708260) Wed May 17 03:57:40 1995
746683 time since boot (secs)
392768 time since reset (secs)
14 Unknown query types
268459 A queries
3044 NS queries
5680 CNAME queries
11364 SOA queries
1008934 PTR queries
44 HINFO queries
680367 MX queries
2369 TXT queries
40 NSAP queries
27 AXFR queries
8336 ANY queries
++ Name Server Statistics ++
(Legend)
RQ RR RIQ RNXD RFwdQ
RFwdR RDupQ RDupR RFail RFErr
RErr RTCP RAXFR RLame ROpts
SSysQ SAns SFwdQ SFwdR SDupQ
SFail SFErr SErr RNotNsQ SNaAns
SNXD
(Global)
1992938 112600 0 19144 63462 60527 194 347 3420 0 5 2235 27 35289 0
14886 1927930 63462 60527 107169 10025 119 0 1785426 805592 35863
[15.255.72.20]
485 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 485 0 0 0 0 0 0 0 485 0
[15.255.152.2]
441 137 0 1 2 108 0 0 0 0 0 0 0 0 0 13 439 85 7 84 0 0 0 0 431 0
[15.255.152.4]
770 89 0 1 4 69 0 0 0 0 0 0 0 0 0 14 766 68 5 7 0 0 0 0 755 0
... <lots of entries deleted>
options {
host-statistics yes;
};Let's look at these statistics one line at a time.
This is when this section of the statistics was dumped. The number in parentheses (800708260) is the number of seconds since the Unix epoch, which was January 1, 1970. Mercifully, BIND converts that into a real date and time for you: May 17, 1995, 3:57:40 a.m.+++ Statistics Dump +++ (800708260) Wed May 17 03:57:40 1995
This is how long the local name server has been running. To convert to days, divide by 86400 (60 × 60 × 24, the number of seconds in a day). This server has been running for about 8.5 days.746683 time since boot (secs)
This is how long the local name server has run since the last reload. You'll probably see this number differ from the time since boot only if the server is a primary master name server for one or more zones. Name servers that are slaves for a zone automatically pick up new data with zone transfers and are not usually reloaded. Since this server has been reset, it is probably the primary master name server for some zone.392768 time since reset (secs)
This name server received 14 queries for data of a type it didn't recognize. Either someone is experimenting with new types, there is a defective implementation somewhere, or Paul needs to upgrade his name server.14 Unknown query types
There have been 268459 address lookups. Address queries are normally the most common type of query.268459 A queries
There have been 3044 name server queries. Internally, name servers generate NS queries when they are trying to look up servers for the root zone. Externally, applications like dig and nslookup can also be used to look up NS records.3044 NS queries
Some versions of sendmail make CNAME queries in order to canonicalize a mail address (replace an alias with the canonical name). Other versions of sendmail use ANY queries instead (we'll get to those shortly). Otherwise, the CNAME lookups are most likely from dig or nslookup.5680 CNAME queries
SOA queries are made by slave name servers to check if their zone data is current. If the data is not current, an AXFR query follows to cause the zone transfer. Since this set of statistics does show AXFR queries, we can conclude that slave name servers load zone data from this server.11364 SOA queries
The pointer queries map addresses to names. Many kinds of software look up IP addresses: inetd, rlogind, rshd, network management software, and network tracing software.1008934 PTR queries
The host-information queries are most likely from someone interactively looking up HINFO records.44 HINFO queries
Mailers like sendmail make mail exchanger queries as part of the normal electronic mail delivery process.680367 MX queries
Some application must be making text queries for this number to be this large. It might be a tool like Harvest, which is an information search and retrieval technology developed at the University of Colorado.2369 TXT queries
This is a relatively new record type used to map domain names to OSI Network Service Access Point addresses.40 NSAP queries
Slave name servers make AXFR queries to initiate zone transfers.27 AXFR queries
ANY queries request records of any type for a name. sendmail is the most common program to use this query type. Since sendmail looks up CNAME, MX, and address records for a mail destination, it will make a query for ANY record type so that all the resource records are cached right away at the local name server.8336 ANY queries
The rest of the statistics are kept on a per-host basis. If you look over the list of hosts your name server has exchanged packets with, you'll find out just how garrulous your name server is -- you'll see hundreds or even thousands of hosts in the list. While the size of the list is impressive, the statistics themselves are only somewhat interesting. We'll explain all the statistics, even the ones with zero counts, although you'll probably find only a handful of the statistics useful. To make the statistics easier to read, you'll need a tool to expand the statistics because the output format is rather compact. We wrote a tool called bstat to do just this. Here's what its output looks like:
hpcvsop.cv.hp.com
485 queries received
485 responses sent to this name server
485 queries answered from our cache
relay.hp.com
441 queries received
137 responses received
1 negative response received
2 queries for data not in our cache or authoritative data
108 responses from this name server passed to the querier
13 system queries sent to this name server
439 responses sent to this name server
85 queries sent to this name server
7 responses from other name servers sent to this name server
84 duplicate queries sent to this name server
431 queries answered from our cache
hp.com
770 queries received
89 responses received
1 negative response received
4 queries for data not in our cache or authoritative data
69 responses from this name server passed to the querier
14 system queries sent to this name server
766 responses sent to this name server
68 queries sent to this name server
5 responses from other name servers sent to this name server
7 duplicate queries sent to this name server
755 queries answered from our cacheRQ is the count of queries received from relay. These queries were made because relay needed information about a zone served by this name server.RQ 441
RR is the count of responses received from relay. These are responses to queries made from this name server. Don't try to correlate this number to RQ, because they are not related. RQ counts questions askedby relay; RR counts answers that relay gave to this name server (because this name server asked relay for information).RR 137
RIQ is the count of inverse queries received from relay. Inverse queries were originally intended to map addresses to names, but that function is now handled by PTR records. Older versions of nslookup use an inverse query on startup, so you may see a nonzero RIQ count.RIQ 0
RNXD is the count of "no such domain" answers received from relay.RNXD 1
RFwdQ is the count of queries received (RQ) from relay that needed further processing before they could be answered. This count is much higher for hosts that configure their resolver (with resolv.conf ) to send all queries to your name server.RFwdQ 2
RFwdR is the count of responses received (RR) from relay that answered the original query and were passed back to the application that made the query.RFwdR 108
RDupQ is the count of duplicate queries from relay. You'll see duplicates only when the resolver is configured (with resolv.conf ) to query this name server.RDupQ 0
RDupR is the count of duplicate responses from relay. A response is a duplicate when the name server can no longer find the original query in its list of pending queries that caused the response.RDupR 0
RFail is the count of SERVFAIL responses from relay. A SERVFAIL response indicates some sort of server failure. Server failure responses often occur because the remote server read a zone data file and found a syntax error. Any queries for data in the zone with the erroneous zone data file will result in a server failure answer from the remote name server. This is probably the most common cause of SERVFAIL responses. Server failure responses also occur when the remote name server tries to allocate more memory and can't, or when the remote slave name server's zone data expires.RFail 0
RFErr is the count of FORMERR responses from relay. FORMERR means that the remote name server said the local name server's query had a format error.RFErr 0
RErr is the count of errors that weren't either SERVFAIL or FORMERR.RErr 0
RTCP is the count of queries received on TCP connections from relay. (Most queries use UDP.)RTCP 0
RAXFR is the count of zone transfers initiated. The count indicates that relay is not a slave for any zones served by this name server.RAXFR 0
RLame is the count of lame delegations received. If this count is not 0, it means that some zone is delegated to the name server at this IP address, and the name server is not authoritative for the zone.RLame 0
ROpts is the count of packets received with IP options set.ROpts 0
SSysQ is the count of system queries sent to relay. System queries are queries that are initiated by the local name server. Most system queries will go to root name servers because system queries are used to keep the list of root name servers up to date. But system queries are also used to find out the address of a name server if the address record timed out before the name server record did. Since relay is not a root name server, these queries must have been sent for the latter reason.SSysQ 13
SAns is the count of answers sent to relay. This name server answered 439 out of the 441 (RQ) queries relay sent to it. I wonder what happened to the two queries it didn't answer . . . .SAns 439
SFwdQ is the count of queries that were sent (forwarded) to relay when the answer was not in this name server's zone data or cache.SFwdQ 85
SFwdR is the count of responses from some name server that were sent (forwarded) to relay.SFwdR 7
SDupQ is the count of duplicate queries sent to relay. It's not as bad as it looks, though. The duplicate count is incremented if the query was sent to any other name server first. So relay might have answered all the queries it received the first time it received them, and the query still counted as a duplicate because it was sent to some other name server before relay.SDupQ 84
SFail is the count of SERVFAIL responses sent to relay.SFail 0
SFErr is the count of FORMERR responses sent to relay.SFErr 0
SErr is the count of sendto( ) system calls that failed when the destination was relay.SErr 0
RNotNsQ is the count of queries received that were not from port 53, the name server port. Prior to BIND 8, all name server queries came from port 53. Any queries from ports other than 53 came from a resolver. BIND 8 name servers query from ports other than 53, however, which makes this statistic useless since you can no longer distinguish resolver queries from name server queries. Hence, BIND 8 dropped RNotNsQ from its statistics.RNotNsQ 0
SNaAns is the count of nonauthoritative answers sent to relay. Out of the 439 answers (SAns) sent to relay, 431 were from cached data.SNaAns 431
SNXD is the count of "no such domain" answers sent to relay.SNXD 0
7.6.2.2. BIND 9 statistics
BIND 9.1.0 is the first version of BIND 9 to keep statistics. You use rndc to induce BIND 9 to dump its statistics:
The name server dumps statistics, as a BIND 8 name server would, to a file called named.stats in its working directory. However, those statistics look completely different from BIND 8's. Here are the contents of the stats file from one of our BIND 9 name servers:% rndc stats
The name server appends a new statistics block (the section between "+++ Statistics Dump +++" and " -- - Statistics Dump -- -") each time it receives a stats command. The number in parentheses (979436130) is, as in earlier stats files, the number of seconds since the Unix epoch. Unfortunately, BIND doesn't convert the value for you, but you can use the date command to convert it to something more readable. For example, to convert 979584113 seconds since the Unix epoch ( January 1, 1970), you could use:+++ Statistics Dump +++ (979436130) success 9 referral 0 nxrrset 0 nxdomain 1 recursion 1 failure 1 --- Statistics Dump --- (979436130) +++ Statistics Dump +++ (979584113) success 651 referral 10 nxrrset 11 nxdomain 17 recursion 296 failure 217 --- Statistics Dump --- (979584113)
Let's now go through these statistics one line at a time.% date -d '1970-01-01 979584113 sec' Mon Jan 15 18:41:53 MST 2001
This is the number of successful queries the name server handled. Successful queries are those that didn't result in referrals or errors.success 651
This is the number of queries the name server handled that resulted in referrals.referral 10
This is the number of queries the name server handled that resulted in responses saying that the type of record the querier requested didn't exist for the domain name it specified.nxrrset 11
This is the number of queries the name server handled that resulted in responses saying that the domain name the querier specified didn't exist.nxdomain 17
This is the number of queries the name server received that required recursive processing to answer.recursion 296
This is the number of queries the name server received that resulted in errors other than those covered by nxrrset and nxdomain.failure 217
These are obviously not nearly as many statistics as a BIND 8 name server keeps, but future versions of BIND 9 will probably record more.
7.6.2.3. Using the BIND statistics
Is your name server "healthy"? How do you know what "healthy" operation looks like? From a single snapshot, you can't really say whether a name server is healthy. You have to watch the statistics generated by your server over a period of time to get a feel for what sorts of numbers are normal for your configuration. These numbers will vary markedly among name servers depending on the mix of applications generating lookups, the type of server (primary master, slave, caching-only), and the level of the zones in the namespace it is serving.One thing to watch for in the statistics is how many queries per second your name server receives. Take the number of queries received and divide by the number of seconds the name server has been running. Paul's BIND 4.9.3 name server received 1992938 queries in 746683 seconds, or approximately 2.7 queries per second -- not a very busy server.[53] If the number you come up with for your name server seems out of line, look at which hosts are making all the queries and decide if it makes sense for them to be making all those queries. At some point you may decide that you need more name servers to handle the load. We'll cover that situation in the next chapter.
[53]Recall that the root name servers, which run plain vanilla BIND, can handle thousands of queries per second.
|  | |
| 7.5. Logging in BIND 8 and 9 |  | 8. Growing Your Domain |
