 |  |

| |
Up to now, we've written a simple XML document that contains references to other XML documents, then we created a stylesheet that combines all those referenced XML documents into a single output document. That's all well and good, but we'll probably want to do more advanced things. For example, it might be useful to generate a document that lists all items ordered by all the customers. It might be useful to sort all the purchase orders by the state to which they were shipped, by the last name of the customer, or to group them by the state to which they were shipped. We'll go through some of these scenarios to illustrate the design challenges we face when generating documents from multiple input files.
Our first challenge will be to generate a listing of all purchase orders and sort them by state. This isn't terribly difficult; we'll simply use the <xsl:sort> element in conjunction with the document() function. Here's the heart of our new stylesheet:
<body>
<h3>Selected Purchase Orders - <i>Sorted by state</i></h3>
<xsl:for-each
select="document(/report/po/@filename)/purchase-order/customer/address/state">
<xsl:sort select="."/>
<xsl:apply-templates select="ancestor::purchase-order"/>
</xsl:for-each>
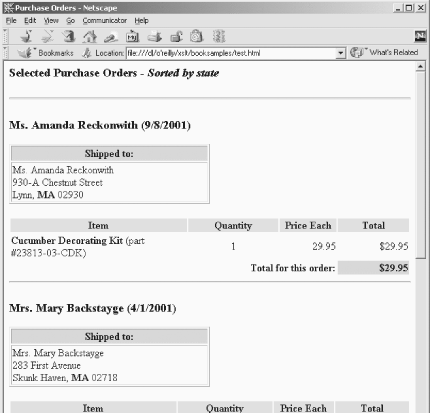
</body>What makes this process slightly challenging is the fact that we're sorting on one thing (the value of the <state> element), then invoking <xsl:apply-templates> against the <purchase-order> ancestor of the <state> element. We simply used the ancestor:: axis to do this. Figure 7-2 shows our output document, sorted by the value of the <state> element in each purchase order.
We mentioned earlier that calling the document() function with an empty string enabled us to access the nodes in the stylesheet itself. We can use this behavior to implement a lookup table. As an example, we'll create a lookup table that replaces an abbreviation such as ME with Maine. We can then use the value from the lookup table as the sort key. More attentive readers might have noticed in our previous example that although the abbreviation MA does indeed sort before the abbreviation ME, a sorted list of the state names themselves would put Maine (abbreviation ME) before Massachusetts (abbreviation MA).
First, we'll create our lookup table. We'll use the fact that a stylesheet can have any element as a top-level element, provided that element is namespace-qualified to distinguish it from the xsl: namespace reserved for stylesheets. Here's the namespace prefix definition and part of the lookup table that uses it:
<?xml version="1.0"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:states="http://new.usps.com/cgi-bin/uspsbv/scripts/content.jsp?D=10090"> <states:name abbrev="AL">Alabama</states:name> <states:name abbrev="AL">Alabama</states:name> <states:name abbrev="AK">Alaska</states:name> <states:name abbrev="AS">American Samoa</states:name> <!-- Most state abbreviations removed to keep this listing brief... --> <states:name abbrev="ME">Maine</states:name> <states:name abbrev="MH">Marshall Islands</states:name> <states:name abbrev="MD">Maryland</states:name> <states:name abbrev="MA">Massachusetts</states:name>
(The namespace mapped to the states prefix is the URL for the official list of state abbreviations from the United States Postal Service.)
To look up values in our table, we'll use the document() function to return the root node of our stylesheet, then we'll look for a <states:name> element with a abbrev attribute that matches the value of the current <state> element in the purchase order we're currently processing. Here's the somewhat convoluted syntax that performs this magic:
<body>
<h3>Selected Purchase Orders - <i>Sorted by state</i></h3>
<xsl:for-each
select="document(/report/po/@filename)/purchase-order/customer/address/state">
<xsl:sort select="document('')/*/states:name[@abbrev=current()]"/>
<xsl:apply-templates select="ancestor::purchase-order"/>
</xsl:for-each>
</body>Notice that we use the document() function twice; once to open the document referred to by the filename element, and once to open the stylesheet itself. We also need to discuss the XPath expression in the select attribute of the <xsl:sort> element. There are four significant parts to this expression:
Indicates that what follows must be a top-level element of the stylesheet. This syntax starts at the root of the document, then has a single element. The element's name can be anything. For our current stylesheet, we could have written the XPath expression like this:
select="document('')/xsl:stylesheet/states:name[@abbrev=current()]"Because the root element of a stylesheet can be either xsl:stylesheet or xsl:transform, it's better to use the asterisk.
Figure 7-3 shows the output from the stylesheet with a lookup table.
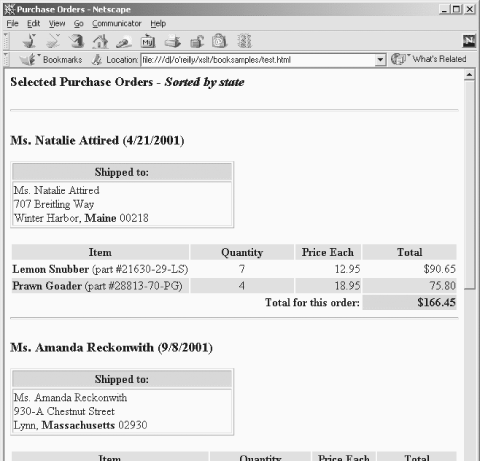
Notice that now the purchase orders have been sorted by the actual name of the state referenced in the address, not by the state's abbreviation. Lookup tables are an extremely useful side effect of the way the document('') function works. You could place a lookup table in another file and you could use the document('') function for other purposes, but the technique we've covered here is the most common way to implement lookup tables.
Our final task will be to group our collection of purchase orders. We'll create a new listing that groups all the purchase orders by the state to which they were shipped. We'll start by attempting the grouping technique we used earlier.
The most efficient grouping technique we used before was to use the XSLT key() function along with the XPath generate-id() function. We create a key for the nodes we want to index (in this case, the <state> elements), then compare each address we find to the first value returned by the key() function. Here's how we define the key:
<xsl:key name="states" match="document(/report/po/@filename)/purchase-order/customer/address" use="state"/>
Unfortunately, the match attribute of the <xsl:key> element can't begin with a call to the document() function. Maybe we could try creating a variable that contains all the nodes we want to use, then use that node-set to create the key:
<xsl:variable name="addresses" select="document(/report/po/@filename)/purchase-order/customer/address"/> <xsl:key name="states" match="$addresses" use="state"/>
This doesn't work either; you can't use a variable in the match attribute. Our hopes for a quick solution to this problem are fading quickly. Complicating the problem is the fact that axes won't help, either. Trying to use the preceding:: axis to see if a previous purchase order came from the current state also doesn't work. Consider this example:
<xsl:if test="not(preceding::address[state=$state])">
When we were working with a single document, the preceding:: axis gave us useful information. Because all of the nodes we're working with are now in separate documents, the various axes defined in XPath won't help. When I ask for any nodes in the preceding:: axis, I only get nodes from the current document. We're going to have to roll up our sleeves and do this the hard way.
Now that we're resigned to grouping nodes with brute force, we'll try to make the process as efficient as possible. For performance reasons, we want to avoid having to call the document() function any more than we have to. This won't be pretty, but here's our approach:
Use the document() function to retrieve the values of all of the <state> elements. To keep things simple, we'll write these values out to a string, separating them with spaces. We'll also use the <xsl:sort> element to sort the <state> elements; that will save us some time later.
Take our string of sorted, space-separated state names (to be precise, they're the values of all the <state> elements) and remove the duplicates. Because things are sorted, I only have to compare two adjacent values. We'll use recursion to handle this.
For each item in our string of sorted, space-separated, unique state names, use the document() function to see which purchase orders match the current state.
This certainly isn't efficient; for each unique state, we'll have to call the document() function once for every filename attribute. In other words, if we had 500 purchase orders from 50 unique states, we would have to open each of those 500 documents 51 times, invoking the document() 25,500 times! It's not pretty, but it works.
Retrieving the values of all <state> elements is relatively straightforward. We'll use the technique of creating a variable whose value contains output from an <xsl:for-each> element:
<xsl:variable name="list-of-states">
<xsl:for-each
select="document(/report/po/@filename)/purchase-order/customer/address/state">
<xsl:sort select="document('')/*/states:name[@abbrev=current()]"/>
<xsl:value-of select="."/><xsl:text> </xsl:text>
</xsl:for-each>
</xsl:variable>This code produces the string "ME MA MA WI" for our current set of purchase orders. Our next step will remove any duplicate values from the list. We'll do this with recursion, using the following algorithm:
Call our recursive template with two arguments: the list of states and the name of the last state we found. the first time we invoke this template, the name of the last state will be blank.
Break the list of states into two parts: The first state in the list, followed by the remaining states in the list.
If the list of states is empty, exit.
If the first state in the list is different from the last state we found, output the first state and invoke the template on the remaining states on the list.
If the first state in the list is the same as the last state we found, simply invoke the template on the remaining states on the list.
Again, we use our technique of calling this template inside an <xsl:variable> element to save the list of unique states for later. Here is the <xsl:variable> element, along with the recursive template that removes duplicate state names from the string:
<xsl:variable name="list-of-unique-states">
<xsl:call-template name="remove-duplicates">
<xsl:with-param name="list-of-states" select="$list-of-states"/>
<xsl:with-param name="last-state" select="''"/>
</xsl:call-template>
</xsl:variable>
<xsl:template name="remove-duplicates">
<xsl:param name="list-of-states"/>
<xsl:param name="last-state" select="''"/>
<xsl:variable name="next-state">
<xsl:value-of select="substring-before($list-of-states, ' ')"/>
</xsl:variable>
<xsl:variable name="remaining-states">
<xsl:value-of select="substring-after($list-of-states, ' ')"/>
</xsl:variable>
<xsl:choose>
<xsl:when test="not(string-length(normalize-space($list-of-states)))">
<!-- If the list of states is empty, do nothing -->
</xsl:when>
<xsl:when test="not($last-state=$next-state)">
<xsl:value-of select="$next-state"/>
<xsl:text> </xsl:text>
<xsl:call-template name="remove-duplicates">
<xsl:with-param name="list-of-states" select="$remaining-states"/>
<xsl:with-param name="last-state" select="$next-state"/>
</xsl:call-template>
</xsl:when>
<xsl:when test="$last-state=$next-state">
<xsl:call-template name="remove-duplicates">
<xsl:with-param name="list-of-states" select="$remaining-states"/>
<xsl:with-param name="last-state" select="$next-state"/>
</xsl:call-template>
</xsl:when>
</xsl:choose>
</xsl:template>At this point, we have a variable named list-of-unique-states that contains the value ME MA WI. Now all we have to do is get each value and output all the purchase orders from each state. We'll use recursion yet again to make this happen. We'll pass our list of unique states to our recursive template, which does the following:
Breaks the string into two parts: the first state in the list and the remaining states.
Outputs a heading for the first state in the list.
Invokes the document() function against each purchase order. If a given purchase order is from the first state in the list, use <xsl:apply-templates> to transform it.
Invokes the template again for the remaining states. If no states remain (the value of normalize-space($remaining-states) is an empty string), we're done.
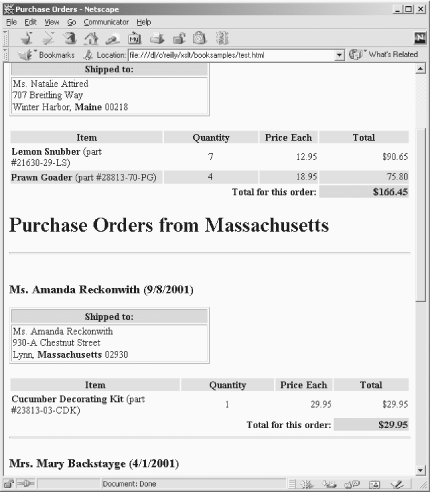
Here is the root template and the recursive template we use to group our data. The result of our hard work looks like Figure 7-4.
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="/report/title"/></title>
</head>
<body>
<h3>Selected Purchase Orders - <i><b>Grouped</b> by state</i></h3>
<xsl:call-template name="group-by-state">
<xsl:with-param name="list-of-unique-states"
select="$list-of-unique-states"/>
</xsl:call-template>
</body>
</html>
</xsl:template>
<xsl:template name="group-by-state">
<xsl:param name="list-of-unique-states"/>
<xsl:variable name="next-state">
<xsl:value-of select="substring-before($list-of-unique-states, ' ')"/>
</xsl:variable>
<xsl:variable name="remaining-states">
<xsl:value-of select="substring-after($list-of-unique-states, ' ')"/>
</xsl:variable>
<hr/>
<h1>Purchase Orders from
<xsl:value-of select="document('')/*/states:name[@abbrev=$next-state]"/>
</h1>
<xsl:for-each
select="document(/report/po/@filename)/purchase-order/customer/address">
<xsl:if test="state=$next-state">
<xsl:apply-templates select="ancestor::purchase-order"/>
</xsl:if>
</xsl:for-each>
<xsl:if test="normalize-space($remaining-states)">
<xsl:call-template name="group-by-state">
<xsl:with-param name="list-of-unique-states"
select="$remaining-states"/>
</xsl:call-template>
</xsl:if>
</xsl:template> |  | |
| 7.3. Invoking the document() Function |  | 7.5. Summary |

Copyright © 2002 O'Reilly & Associates. All rights reserved.